🔥 ICML 2025 Review Results are Coming! Fair or a Total Disaster? 🤯
-
ICML 2025 review results will be disclosed soon, and the reactions will be explosive! Some might be celebrating, some may be outraged, and others could just be confused.

 Did your paper survive the brutal review process?
Did your paper survive the brutal review process?
 Were the reviews fair or just random rejection roulette?
Were the reviews fair or just random rejection roulette?
 Overworked reviewers? Unfair scoring? Biased decisions?
Overworked reviewers? Unfair scoring? Biased decisions?Let’s Break It Down
 Review Quality – Are reviewers actually reading papers, or just speed-running decisions?
Review Quality – Are reviewers actually reading papers, or just speed-running decisions?
 Review Workload – Is ICML expecting too much from reviewers?
Review Workload – Is ICML expecting too much from reviewers?
 Scoring System Madness – Are papers judged fairly, or is it a dice roll?
Scoring System Madness – Are papers judged fairly, or is it a dice roll?
 ️ Transparency Issues – Why is the review process still a black box?
️ Transparency Issues – Why is the review process still a black box?
 Declining Paper Quality? – Are we seeing more “spam submissions” or just cutthroat competition?
Declining Paper Quality? – Are we seeing more “spam submissions” or just cutthroat competition?Tell Us Your Story!
 Did your paper make it, or did ICML crush your dreams?
Did your paper make it, or did ICML crush your dreams?
 What’s the most absurd review you received?
What’s the most absurd review you received?
 Reviewers, are you drowning in paper assignments?
Reviewers, are you drowning in paper assignments?Register (verified or anonymous) to drop your experiences below! Anonymous rants are also welcome.


-
If you feel upset, check this paper out

-
Here is a crowed sourced score distribution for this year:
https://papercopilot.com/statistics/icml-statistics/icml-2025-statistics/And, you can also refer to the previous year's score distributions in relation to accept/reject:
https://papercopilot.com/statistics/icml-statistics/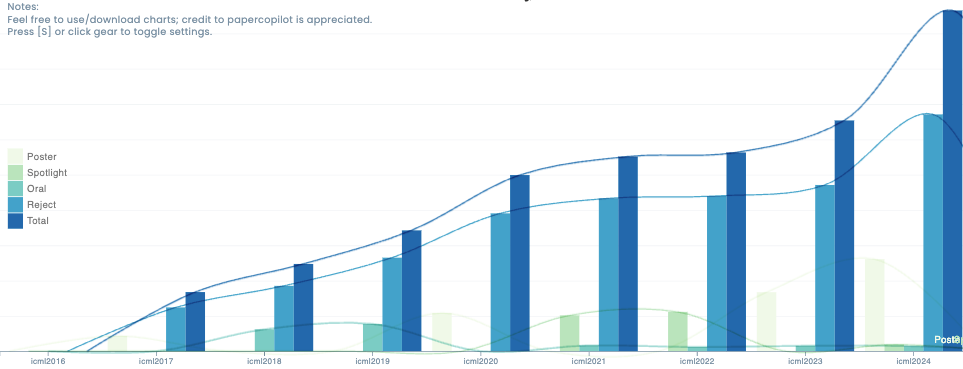
-
Just heard this from a fellow researcher who’s reviewing for ICML 2025:
"... They keep enforcing mandatory reviews for authors, ... The review process has gotten way too complicated - each paper requires filling out over ten different sections. It’s already unpaid labor, and now it feels like they’re squeezing reviewers dry. Honestly, this kind of over-engineered reform is making things worse, not better. Review quality is only going to keep declining if it keeps going this way.”
 Yikes. Anyone else feeling or hearing the same?
Yikes. Anyone else feeling or hearing the same? -
Here is a crowed sourced score distribution for this year:
https://papercopilot.com/statistics/icml-statistics/icml-2025-statistics/And, you can also refer to the previous year's score distributions in relation to accept/reject:
https://papercopilot.com/statistics/icml-statistics/ -
If you feel upset, check this paper out
-
Just heard this from a fellow researcher who’s reviewing for ICML 2025:
"... They keep enforcing mandatory reviews for authors, ... The review process has gotten way too complicated - each paper requires filling out over ten different sections. It’s already unpaid labor, and now it feels like they’re squeezing reviewers dry. Honestly, this kind of over-engineered reform is making things worse, not better. Review quality is only going to keep declining if it keeps going this way.”
Yikes. Anyone else feeling or hearing the same?@lelecao said in
ICML 2025 Review Results are Coming! Fair or a Total Disaster? 🤯: Just heard this from a fellow researcher who’s reviewing for ICML 2025:"... They keep enforcing mandatory reviews for authors, ... The review process has gotten way too complicated - each paper requires filling out over ten different sections. It’s already unpaid labor, and now it feels like they’re squeezing reviewers dry. Honestly, this kind of over-engineered reform is making things worse, not better. Review quality is only going to keep declining if it keeps going this way.”
Yikes. Anyone else feeling or hearing the same?Peer review should stay unpaid as I know. Payments may cause great biases and unfairness though people love money including both you and me.
 What are other ways for simplification?
What are other ways for simplification? -
ICML — also known as I Cannot Manage Life. The world’s most famous reviewer torture conference, held annually. You submit one paper, review five. Doesn’t matter if it’s not your area — you’ll have to figure it out anyway. Comments need to be detailed, long, and exhaustive. Finishing one review basically feels like writing half a paper. No money for reviews, just dedicating all your pure love. And after all those late-night comments? Guess what — the AC might not even consider them, and even a paper with all-positive reviews can still get rejected.
-
ICML — also known as I Cannot Manage Life. The world’s most famous reviewer torture conference, held annually. You submit one paper, review five. Doesn’t matter if it’s not your area — you’ll have to figure it out anyway. Comments need to be detailed, long, and exhaustive. Finishing one review basically feels like writing half a paper. No money for reviews, just dedicating all your pure love. And after all those late-night comments? Guess what — the AC might not even consider them, and even a paper with all-positive reviews can still get rejected.
-
I posted more astonishingly funny reviews here:
https://cspaper.org/topic/26/the-icml-25-review-disaster-what-does-k-in-k-nn-mean
-

334 222 234 124 335
223 344 445 233 122 -
 ICML 2025 Sample Paper Scores reported by communities
ICML 2025 Sample Paper Scores reported by communitiesPaper / Context Scores Notes Theoretical ML paper 4 4 4 3 Former ICLR desk-reject; ICML gave higher scores, hopeful after rebuttal. Attention alternative 3 2 1 2 Lacked compute to run LLM benchmarks as requested by reviewers. GNN Paper #1 2 2 2 2 Reviewer misunderstanding; suggested irrelevant datasets. GNN Paper #2 2 1 1 2 Criticized for not being SOTA despite novelty. Multilingual LLM 1 1 2 3 Biased reviewer compared with own failed method. FlashAttention misunderstanding 1 2 2 3 Reviewer misread implementation; lack of clarity blamed. Rebuttal-acknowledged paper 4 3 2 1 → 4 3 2 2 Reviewer accepted corrected proof. Real-world method w/o benchmarks 3 3 3 2 Reviewer feedback mixed; lacks standard benchmarks. All ones 1 1 1 Author considering giving up; likely reject. Mixed bag (NeurIPS resub) 2 2 1 Reviewer ignored results clearly presented in own section. Exhaustive range 2 3 4 5 “Only needed a 1 to collect all scores.” Borderline paper (Reddit) 2 3 5 5 Rejections previously; hopeful this time. Balanced but low 3 2 2 2 Reviewer feedback limited; author unsure of chances. Another full range 1 3 5 Author confused by extremes; grateful but puzzled. Extra reviews 1 2 3 3 3 One adjusted score during rebuttal; one reviewer stayed vague. Flat scores 3 3 3 3 Uniformly weak accept, uncertain accept probability. High variance 4 4 3 1 Strong and weak opinions; outcome unclear. Review flagged as LLM-generated 2 1 3 3 LLM tools flagged 2 reviews as possibly AI-generated. Weak accept cluster 3 3 2 Reviewers did not check proofs or supplementary material. Very mixed + LLM suspicion 2 3 4 1 2 Belief that two reviews are unfair / LLM-generated. Lower tail 2 2 1 1 Reviewer comments vague; possible LLM usage suspected. Low-medium range 1 2 3 Concerns reviewers missed paper’s main points. Long tail + unclear review 3 2 2 1 Two willing to adjust; one deeply critical with little justification. Slightly positive 4 3 2 Reviewer praised work but gave 2 anyway. Mixed high 4 2 2 5 Confusing mix, but "5" may pull weight. Middle mix 2 2 4 4 Reviewers disagree on strength; AC may play key role. More reviews than expected 3 3 3 2 2 2 Possibly emergency reviewers assigned. Strong first reviewer 3 2 2 Others gave poor quality reviews; unclear chance. Pessimistic mix 3 2 1 Reviewer willing to increase, but others not constructive. Hopeless mix 1 2 2 3 Reviewer missed key ideas; debating NeurIPS resub. Offline RL 2 2 2 Still decide to rebuttal, but not enough space for additional results Counterfactual exp. 1 2 2 3 Got 7 7 8 8 from ICLR yet still rejected by ICLR2025! This time the scores are ridiculous! -
 ICML 2025 Review – Most Outstanding Issues
ICML 2025 Review – Most Outstanding IssuesSources are labeled whenever suited
1. 🧾 Incomplete / Low-Quality Reviews
- Several submissions received no reviews at all (Zhihu).
- Single-review papers despite multi-review policy.
- Some reviewers appeared to skim or misunderstand the paper.
- Accusations that reviews were LLM-generated: generic, hallucinated, overly verbose (Reddit).
2.
Unjustified Low Scores- Reviews lacked substantive critique but gave 1 or 2 scores without explanation.
- Cases where positive commentary was followed by a low score (e.g., "Good paper" + score 2).
- Reviewers pushing personal biases (e.g., “you didn’t cite my 5 papers”).
3. 🧠 Domain Mismatch
- Theoretical reviewers assigned empirical papers and vice versa (Zhihu).
- Reviewers struggling with areas outside their expertise, leading to incorrect comments.
4.
 Rebuttal System Frustrations
Rebuttal System Frustrations- 5000-character rebuttal limit per reviewer too short to address all concerns.
- Markdown formatting restrictions (e.g., no multiple boxes, limited links).
- Reviewers acknowledged rebuttal but did not adjust scores.
- Authors felt rebuttal phase was performative rather than impactful.
5. 🪵 Bureaucratic Review Process
- Reviewers forced to fill out many structured fields: "claims & evidence", "broader impact", etc.
- Complaint: “Too much form-filling, not enough science” (Zhihu).
6.
Noisy and Arbitrary Scoring- Extreme score variance within a single paper (e.g., 1/3/5).
- Scores didn’t align with review contents or compared results.
- Unclear thresholds and lack of transparency in AC decision-making.
7.
 Suspected LLM Reviews (Reddit-specific)
Suspected LLM Reviews (Reddit-specific)- Reviewers suspected of using LLMs to generate long, vague reviews.
- Multiple users ran reviews through tools like GPTZero / DeepSeek and got LLM flags.
8.
Burnout and Overload- Reviewers overloaded with 5 papers, many outside comfort zone.
- No option to reduce load, leading to surface-level reviews.
- Authors and reviewers both expressed mental exhaustion.
9.
 Review Mismatch with Paper Goals
Review Mismatch with Paper Goals- Reviewers asked for experiments outside scope or compute budget (e.g., run LLM baselines).
- Demands for comparisons against outdated or irrelevant benchmarks.
10.
 ️ Lack of Accountability / Transparency
️ Lack of Accountability / Transparency- Authors wished for reviewer identity disclosure post-discussion to encourage accountability.
- Inconsistent handling of rebuttal responses across different ACs and tracks.
-
Even if a rebuttal is detailed and thorough, reviewers often only ACK without changing the score. This usually means they accept your response but don’t feel it shifts their overall assessment enough. Some see added experiments as “too late” or not part of the original contribution. Others may still not fully understand the paper but won’t admit it. Unfortunately, rebuttals prevent score drops more often than they raise scores.

-
Even if a rebuttal is detailed and thorough, reviewers often only ACK without changing the score. This usually means they accept your response but don’t feel it shifts their overall assessment enough. Some see added experiments as “too late” or not part of the original contribution. Others may still not fully understand the paper but won’t admit it. Unfortunately, rebuttals prevent score drops more often than they raise scores.
-
I’d like to add by amplifying a few parts of the experience shared by XY天下第一漂亮, because it represents not just a “review gone wrong” — but a systemic breakdown in how feedback, fairness, and reviewer responsibility are managed at scale.
A Story of Two "2"s: When Reviews Become Self-Referential Echoes
The core absurdity here lies in the two low-scoring reviews (Ra and Rb), who essentially admitted they didn’t fully understand the theoretical contributions, and yet still gave definitive scores. Let's pause here: if you're not sure about your own judgment, how can you justify a 2?
Ra: “Seems correct, but theory isn’t my main area.”
Rb: “Seems correct, but I didn’t check carefully.”
That’s already shaky. But it gets worse.
After a decent rebuttal effort, addressing Rb’s demands and running additional experiments, Rb acknowledges that their initial concerns were “unreasonable,” but then shifts the goalposts. Now the complaint is lack of SOTA performance. How convenient. Ra follows suit by quoting Rb, who just admitted they were wrong, and further downgrades the work as “marginal” because SOTA wasn’t reached in absolute terms.
This is like trying to win a match where the referee changes the rules midway — and then quotes the other referee’s flawed call as justification.
Rb’s Shapeshifting Demands: From Flawed to Absurd
After requesting fixes to experiments that were already justified, Rb asks for even more — including experiments on a terabyte-scale dataset.
Reminder: this is an academic conference, not a hyperscale startup. The author clearly explains the compute budget constraint, and even links to previous OpenReview threads where such experiments were already criticized. Despite this, Rb goes silent after getting additional experiments done.
Ra, having access to these new results, still cites Rb’s earlier statement (yes, the one Rb backtracked from), calling the results "edge-case SOTA" and refusing to adjust the score.
Imagine that: a reviewer says, “I don’t fully understand your method,” then quotes another reviewer who admitted they were wrong, and uses that to justify rejecting your paper.
Rebuttal Becomes a Farce
The third reviewer, Rc, praises the rebuttal but still refuses to adjust the score because “others had valid concerns.” So now we’re in full-on consensus laundering, where no single reviewer takes full responsibility, but all use each other’s indecisiveness as cover.
This is what rebuttals often become: not a chance to clarify, but a stress test to see whether the paper survives collective reviewer anxiety and laziness.
The Real Cost: Mental Health and Career Choices
What hits hardest is the closing reflection:
"A self-funded GPU, is it really enough to paddle to publication?"
That line broke me. Because many of us have wondered the same. How many brilliant, scrappy researchers (operating on shoestring budgets, relying on 1 GPU and off-hours) get filtered out not because of lack of ideas, but because of a system designed around compute privilege, reviewer roulette, and metrics worship?
The author says they're done. They're choosing to leave academia after a series of similar outcomes. And to be honest, I can't blame them.
A Final Note: What’s Broken Isn’t the Review System — It’s the Culture Around It
It’s easy to say "peer review is hard" or "everyone gets bad reviews." But this case isn’t just about a tough review. It’s about a system that enables vague criticisms, shifting reviewer standards, and a lack of accountability.
If we want to keep talent like the sharing author in the field, we need to:
- Reassign reviewers when they admit they're out-of-domain.
- Disallow quoting other reviewers as justification.
- Add reviewer accountability (maybe even delayed identity reveal).
- Allow authors to respond once more if reviewers shift arguments post-rebuttal.
- Actually reduce the bureaucratic burden of reviewing.
To XY天下第一漂亮 — thank you for your courage. This post is more than a rant. It’s a mirror.
And yes, in today’s ML publishing world:
Money, GPUs, Pre-train, SOTA, Fake results, and Baseline cherry-picking may be all you need; but honesty and insight like yours are what we actually need.
 Wish all best of luck!
Wish all best of luck! 


 between rebuttal
between rebuttal  ️ and submission
️ and submission  .
.