[👂Podcast] Is GPT-4 Secretly Reviewing Your Paper? 🤖
-
 Listen to the podcast summary here (via NotebookLM)
Listen to the podcast summary here (via NotebookLM)Stanford Study Finds Up to 16.9% of Peer Reviews at Top AI Conferences May Be AI-Generated
A 2024 case study from Stanford University has dropped a bombshell: up to 16.9% of peer reviews at major AI conferences like ICLR, NeurIPS, EMNLP, and CoRL might have been written or heavily edited by LLMs like ChatGPT.
Listen to the podcast summary here (via NotebookLM)
🧾 What's Going On?
Peer review is the gold standard of academic quality control. But what happens when the reviewers themselves are using AI to write those reviews?
Stanford researchers asked that very question. They developed a method to estimate the proportion of AI-generated or heavily AI-edited reviews in large-scale peer review datasets, and then applied it to real reviews from AI-focused conferences.
Spoiler alert: it’s already happening, and more than we thought.
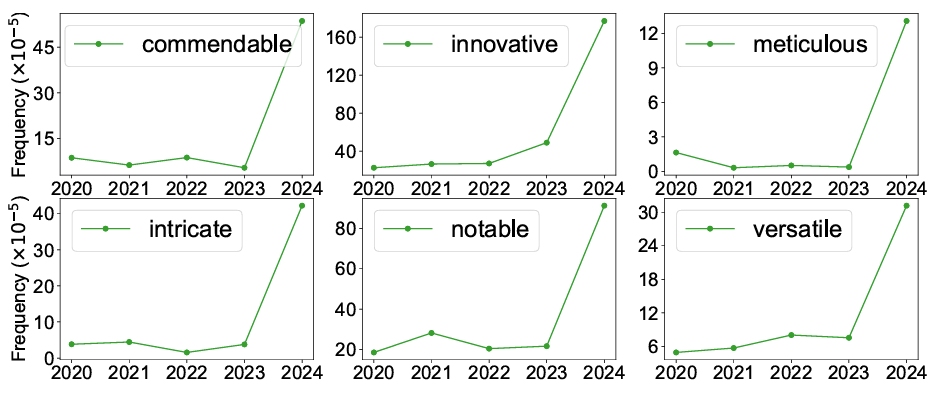
Shift in adjective frequency in ICLR 2024 peer reviews Key Findings
Key Findings- Estimated 6.5% to 16.9% of reviews from top AI conferences were substantially written or revised by LLMs like GPT-4.
- Certain adjectives like “commendable,” “meticulous,” “complex” appeared 10x to 30x more frequently, suggesting signature LLM writing style.
- Use of GPT correlated with:
 Lower reviewer self-confidence
Lower reviewer self-confidence- Late submissions (especially in the final 3 days)
- No response during rebuttal phase
- Reviews that mimic other reviewers (homogeneity)
- Fewer academic references ("et al." = more human-like)
By contrast, journals like Nature Portfolio showed no spike in AI-generated reviews post-ChatGPT, highlighting a cultural difference between broad science communities and the ML world.
 How They Measured It
How They Measured ItStanford didn't rely on flaky LLM detectors (we know how unreliable those can be). Instead, they used a maximum likelihood estimation framework to compare the statistical fingerprints of human vs. AI-written text.
Here's the 4-step method:
- Prompt a GPT model with reviewer guidelines to generate synthetic AI reviews.
- Compare writing patterns (word choice, phrasing, structure) between human-written and GPT-written corpora.
- Validate the method on synthetic mixed datasets with known AI/Human ratios.
- Apply the model to real review datasets from ICLR, NeurIPS, EMNLP, and CoRL.
The method showed <2.4% error rate when estimating LLM usage on test data. Pretty solid.
Podcast-Style SummaryIf you're short on time, the team used NotebookLM to generate a voice-based podcast that breaks down the paper conversationally. Check it out:
 NotebookLM Audio Summary
NotebookLM Audio Summary
 What Does This Mean?
What Does This Mean?This isn't just about who wrote the review — it's about trust in the peer review process.
- Will AI make reviews more consistent… or more superficial?
- Are we okay with reviewers outsourcing their judgment to GPT?
- Should conferences regulate LLM use for reviews?
- Will review quality collapse under pressure + automation?
More broadly, this study shines light on how LLMs blur the line between automation and authorship, and raises crucial questions for the future of academic integrity.
🧠 Final Thoughts
Yes, the study has its limitations: only 4 conferences analyzed, and only GPT-4 was used for LLM baselines. But it opens up a timely and urgent conversation:
“What happens when the guardians of academic quality start letting machines speak for them?”
Now’s the time for serious discussion and policy work. Because whether we like it or not, AI is already reviewing your AI paper.
 Paper link: arXiv:2403.07183
Paper link: arXiv:2403.07183
Register (verified or anonymous) to leave your thoughts below
")
